Computer Organization
What would be the best way to build scalable, parallel execution engines?
In 1966, Michael J. Flynn, proposed a taxonomy based on two dimensions, the parallelism of data and instructions 1.
A purely sequential machine has a single instruction stream and a single data stream and the acronym SISD. A machine that applies the same instruction on multiple data elements is a SIMD machine, short for Single Instruction Multiple Data. Machines that have multiple instruction streams operating on a single data element as used in fault-tolerant and redundant system designs, and carry the designation MISD, Multiple Instruction Single Data. The Multiple Instruction Multiple Data machine, or MIMD, consists of many processing elements simultaneously operating on different data.
The diagram below shows the Flynn Taxonomy 2:
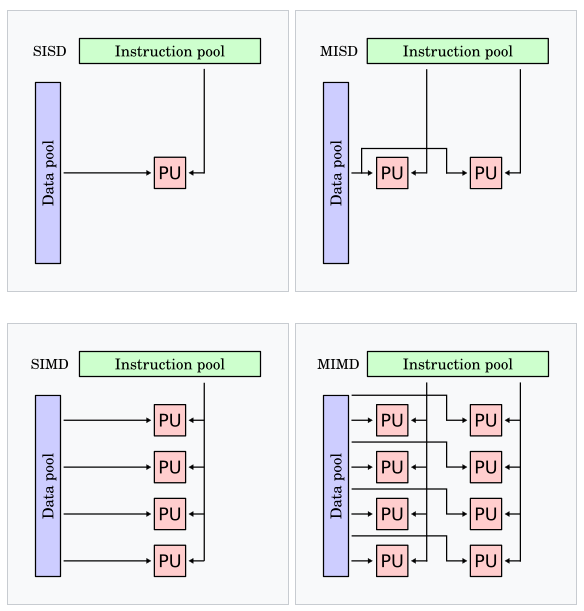
Flynn's Parallel Computer Taxonomy
The availability of inexpensive microprocessors has made it possible to create cost-effective parallel MIMD machines. A parallel program running on such a distributed architecture consists of a collection of sequential programs. A parallel algorithm for these distributed memory architectures requires designing a data structure decomposition that can be stored in the memory of the different processing nodes, a program decomposition that transforms these blocks of the data structure, and an exchange phase to communicate dependent data among the nodes.
For these algorithms to work well, the computation phase and the data exchange phase need to be coordinated such that the program does not need to wait. Distributed Memory Machine (DMM) algorithms have been studied to categorize them as a function of this constraint. This categorization has become known as the Seven Dwarfs 3. Later refinement has expanded that to thirteen dwarfs.
The algorithms that work well for this parallel model of computation all share the same information exchange dynamic. Either, the computation does not depend on remote data, the so-called embarrasingly parallel algorithms, or when there is a dependency, the computational complexity of the node execution scales faster than the data exchange complexity, yielding so-called weak scaling algorithms that can be made efficient by scaling up the data structure size. Any other information exchange will diminish the compute efficiency of the distributed machine.
Supercomputers that are purpose-build for capability have been constructed as DMMs since the early ’90s, attesting to the success of the Distributed Memory Machine model. And thirty years of empirical evidence has shown that designing these DMM algorithms is difficult. The dynamic behavior of the actual execution must be understood to be able to design and optimize the distributed program to maximize resource efficiency.
The simplest architecture of these parallel programs use the same program to run on all the processors, and is referred to as SPMD algorithms, short for Single Program Multiple Data. The single program will have access to process identifiers that allow it to specialize behavior, such as accessing external I/O, or customize behavior for edge cases. The SPMD runtime is responsible for creating the execution topology and configure these identifiers.
The MIMD approach, however, is not isolated to just the Distributed Memory Machine. Real-time data acquisition, signal processing, and control systems also demand high-performance parallel execution, but systems for these use cases tend to be constructed differently. Instead of blocking the computation to create subprograms that can be executed on a Stored Program Machine, real-time system tend to favor distributed and balanced data paths designed to never require dynamic reconfiguration. The Synchronous Data Flow model of execution was tailored to design and reason over these parallel execution patterns.
Whereas Distributed Memory Machines require coarse-grain parallelism to work, real-time systems tend to favor fine-grain parallelism. Fine-grain parallel systems offer lower latencies, and an increasingly important benefit, energy efficiency. In the next chapter, we’ll discuss the techniques used to design spatial mappings for fine-grained parallel machines.
Footnotes
[1] Flynn, Michael J. (December 1966), Very high-speed computing systems
[2] Flynn’s taxonomy Wikipedia
[3] The Landscape of Parallel Computing Research: A View from Berkeley The Seven Dwarfs